A hitchhiker's guide into LLM post-training
EP1 of Tokens for Thoughts
By Han Fang, Karthik Abinav Sankararaman
This document serves as a guide to understanding the basics of LLM post-training. It covers the complete journey from pre-training to instruction-tuned models. The guide walks through the entire post-training lifecycle, exploring:
This is our first note and we will discuss post-training intermediate topics next. Please DM us what other topics you would like to learn too. Hope you enjoy!
A base model (or a pre-trained model) is usually created by pre-training on large-scale text and image data [1][2]. The primary goal of pre-training is to encode the world’s (in a narrow sense, the Internet’s) knowledge into the model. The training objective is quite straightforward: the model is trained to predict the next token over many different sequences prior to it [1]. However, while a base model can be very knowledgeable, the training objective of next token prediction also makes it less useful in most applications [3].
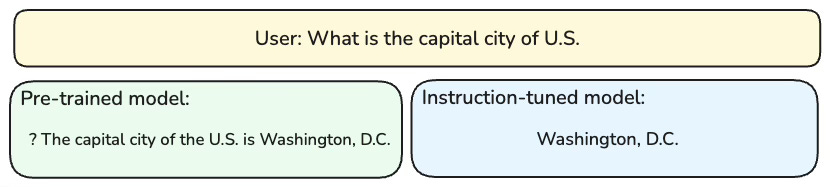
The following conceptual comparison (Figure 1) will give you a rough sense of the difference in their behaviors. When prompted with the same question, “What is the capital city of U.S”. Note that here the user prompt does not have a question mark at the end. A pre-trained model (left), which was trained to predict the next token, will firstly predict the question mark (i.e. ?) before finishing the rest of the sentence. On the other hand, an instruction-tuned model, will respond “Washington, D.C.” directly, since it was usually trained to answer a user’ question as opposed to continuation [4].
Figure 1. The journey from pre‑training to an instruct‑tuned model.
In order to make the large language model (LLM) actually helpful in answering questions, we usually take a base model and go through post-training (also known as fine-tuning). Instead of using the web corpora crawled from the Internet, post-training data is usually much smaller in size and far more curated [5]. Post-training is used to align model’s behaviors (helpful, honesty, harmless) and improve its capabilities that were accrued from pre-training. There are quite a few popular techniques for post-training, such as supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). After DeepSeek R1 [6], there was an emergence of reinforcement learning with verifiable rewards (RLVR) which is very effective in improving the model’s reasoning and coding capabilities [7].